In this practical, I’ll demonstrate how to apply seasonal and panel data approaches to TSA in R.
Visualising and decomposing seasonal patterns
Question: “How does an athlete’s performance score vary seasonally over the training and competition cycle?”
Analysis
In athletics, performance can fluctuate over the year due to training cycles/ peaking for major events/ recovery periods.
This code simulates a monthly performance score series (higher is better) with seasonal peaks (perhaps representing better performance in the summer months) and random variation:
Code
library(ggplot2)library(forecast)
Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo
Code
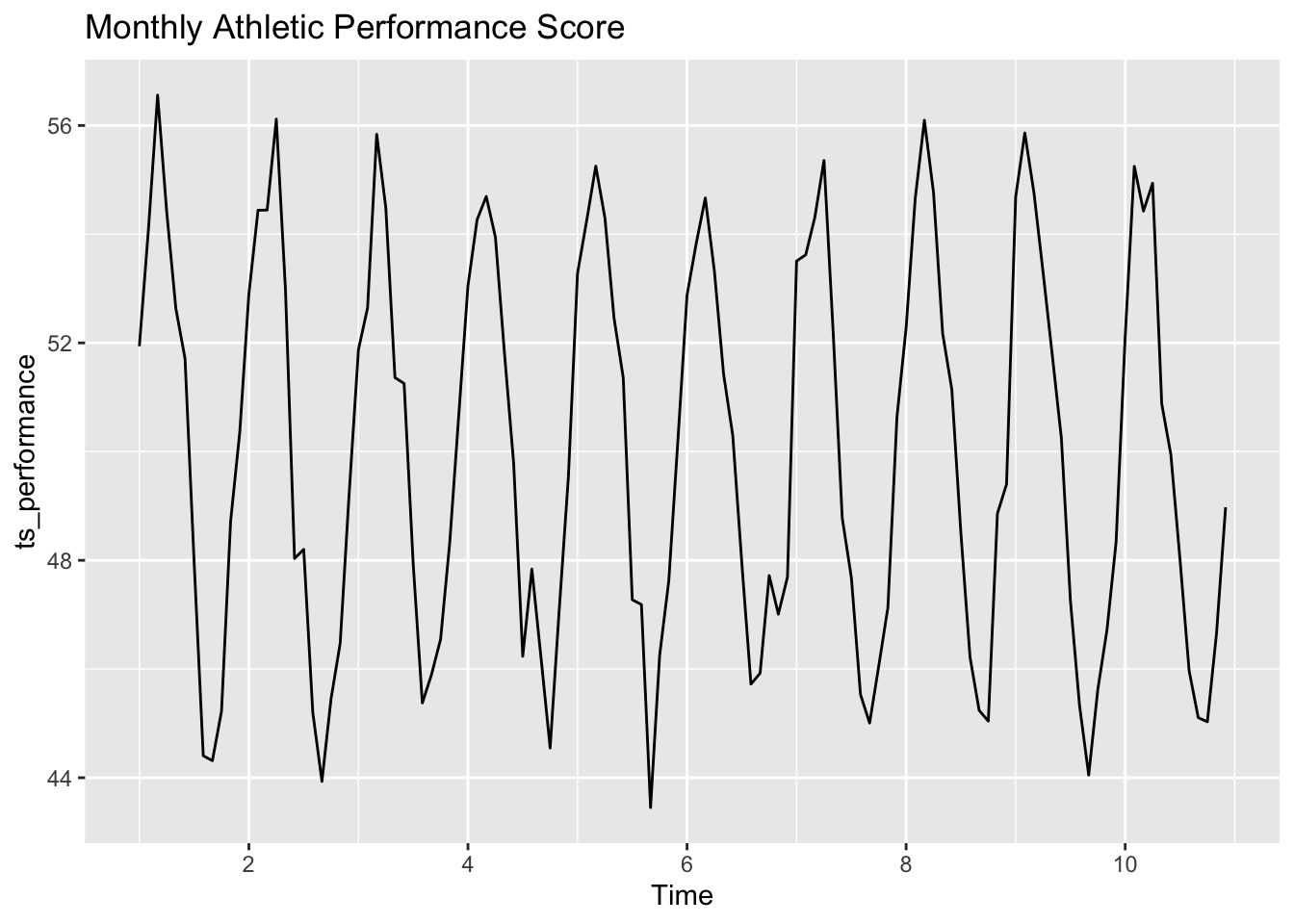
set.seed(123)time <-1:120# Simulate a seasonal pattern (e.g., peak performance during summer months)seasonality <-5*sin(2* pi * time /12)noise <-rnorm(120, mean =0, sd =1)performance <-50+ seasonality + noise # Base performance score with seasonal variationts_performance <-ts(performance, frequency =12)autoplot(ts_performance) +ggtitle("Monthly Athletic Performance Score")
Decomposition
Decomposition helps answer:
“What parts of the performance trend are driven by seasonality versus long-term improvements or random factors?”
Code
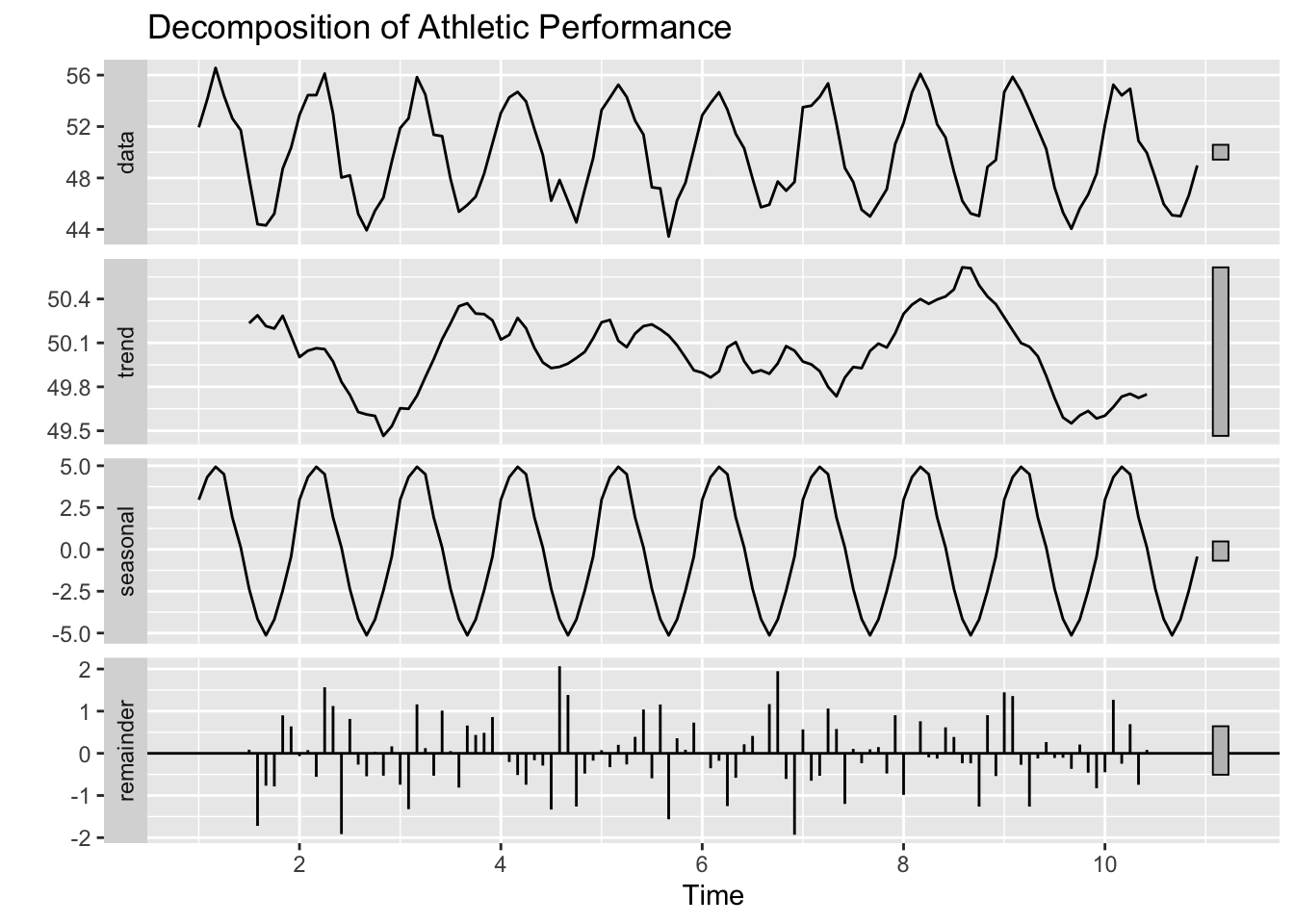
decomposed <-decompose(ts_performance)autoplot(decomposed) +ggtitle("Decomposition of Athletic Performance")
Interpretation
Trend: Could reflect gradual improvement from training over several years.
Seasonality: Highlights cyclical peaks (e.g., performance boosts during competition season).
Noise: Random fluctuations due to day-to-day conditions.
Forecast Opportunity
After decomposing, we can forecast future performance by modeling the seasonal component separately.
This might help coaches schedule training to maintain peak performance during competitions.
Code
library(ggplot2)library(forecast)set.seed(123)time <-1:120# Simulate performance data with a seasonal pattern (e.g., peak during competition months)seasonality <-5*sin(2* pi * time /12)noise <-rnorm(120, mean =0, sd =1)performance <-50+ seasonality + noisets_performance <-ts(performance, frequency =12)# Decompose time seriesdecomposed <-decompose(ts_performance)autoplot(decomposed) +ggtitle("Decomposition of Athletic Performance")
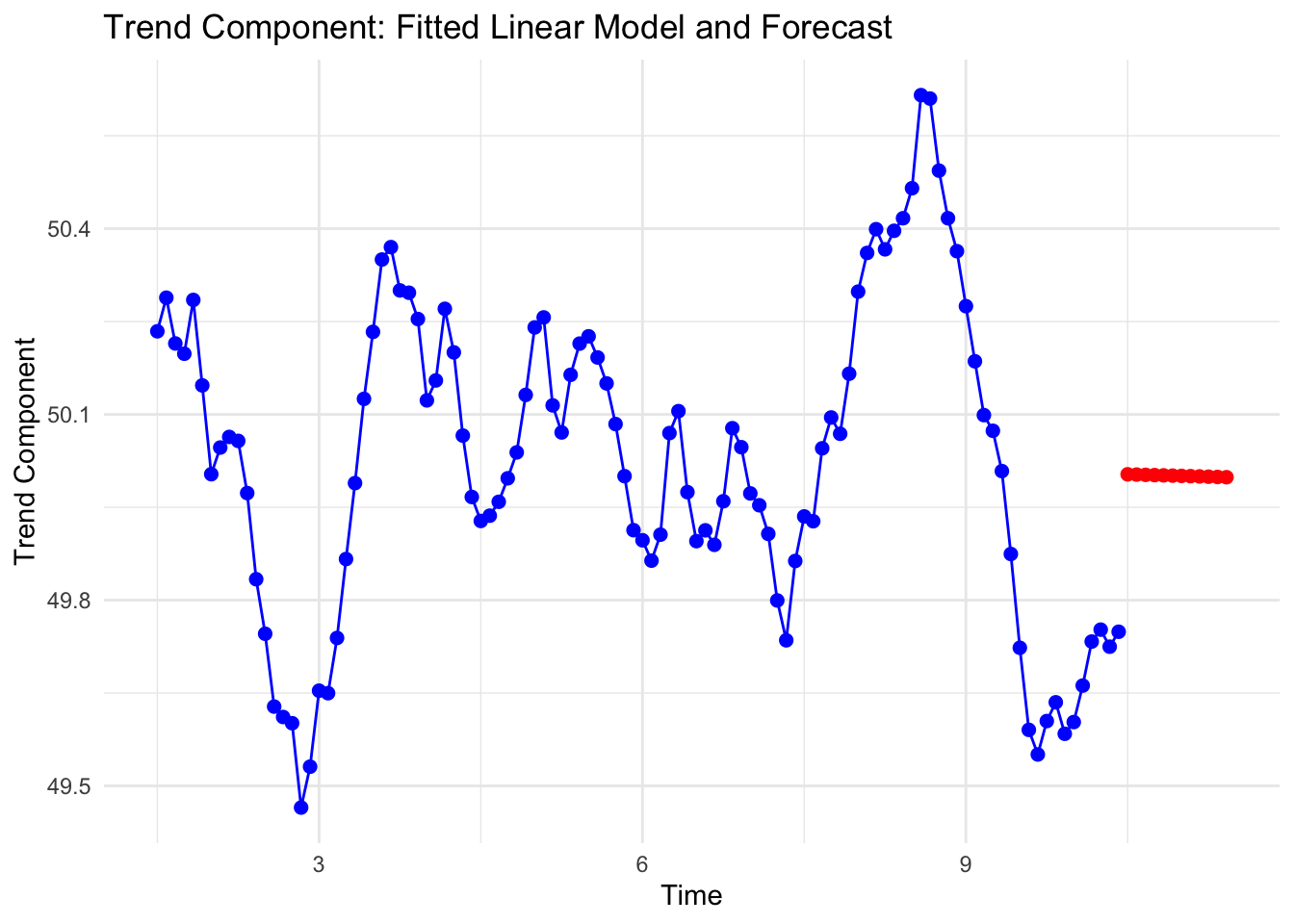
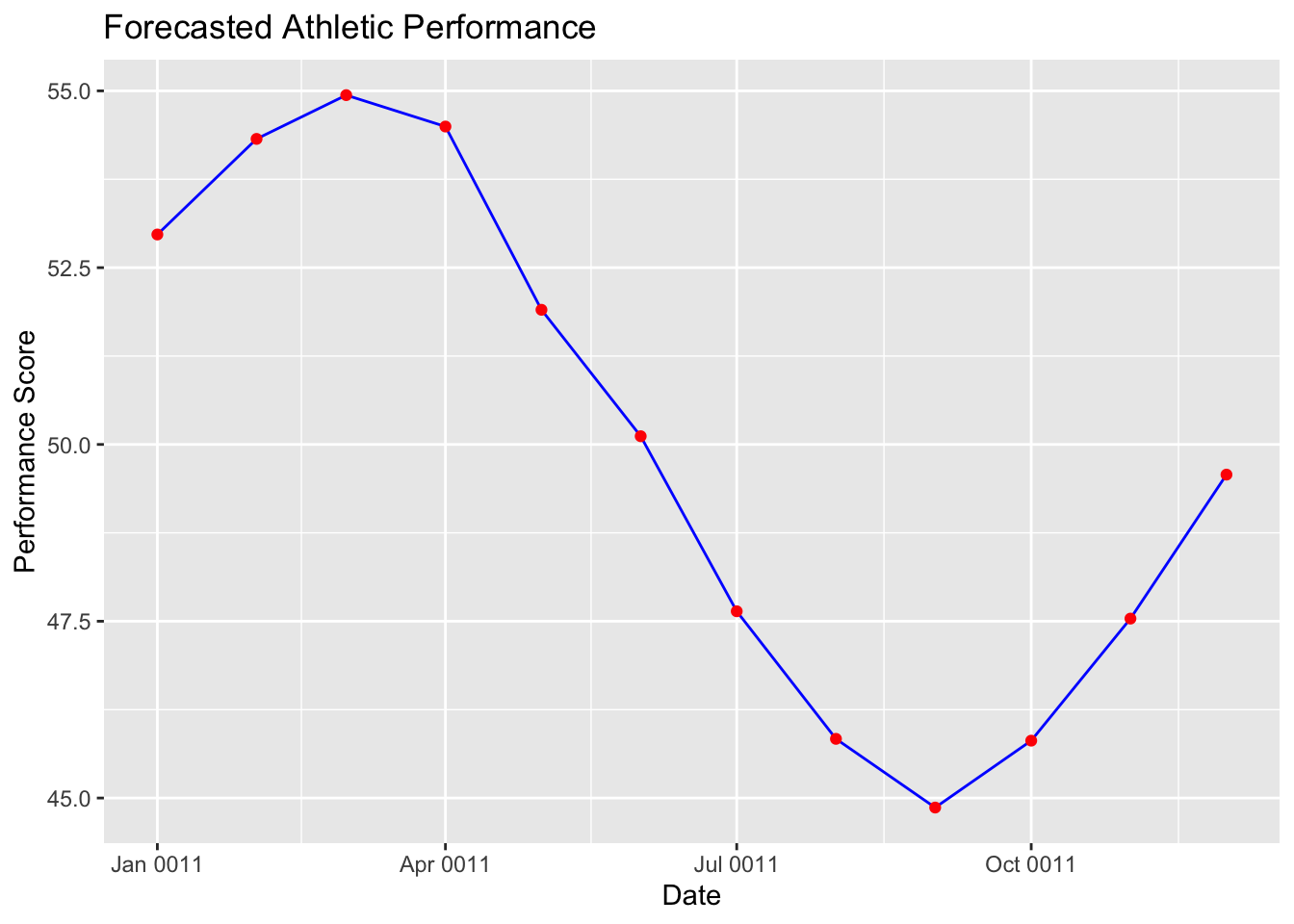
Since the seasonal pattern is assumed to repeat, we focus on forecasting the underlying trend.
Here, we extract the trend component (ignoring the edge NAs) and fit a simple linear model.
Code
trend <- decomposed$trendtime_idx <-time(ts_performance)valid <-!is.na(trend)trend_clean <- trend[valid]time_clean <- time_idx[valid]# Fit linear model to trend componenttrend_model <-lm(trend_clean ~ time_clean)summary(trend_model)
Call:
lm(formula = trend_clean ~ time_clean)
Residuals:
Min 1Q Median 3Q Max
-0.57727 -0.13959 0.01491 0.17777 0.60262
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.056757 0.061689 811.436 <2e-16 ***
time_clean -0.005097 0.009491 -0.537 0.592
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2562 on 106 degrees of freedom
Multiple R-squared: 0.002714, Adjusted R-squared: -0.006694
F-statistic: 0.2885 on 1 and 106 DF, p-value: 0.5923
Code
# Forecast trend for next 12 monthsfuture_time <-seq(max(time_clean) +1/12, by =1/12, length.out =12)trend_forecast <-predict(trend_model, newdata =data.frame(time_clean = future_time))# Create data frames for plottingdf_trend <-data.frame(time = time_clean, trend = trend_clean)df_forecast <-data.frame(time = future_time, trend = trend_forecast)# Visualise trend, fitted line, forecastlibrary(ggplot2)ggplot() +geom_point(data = df_trend, aes(x = time, y = trend), color ="blue", size =2) +geom_line(data = df_trend, aes(x = time, y = trend), color ="blue") +geom_line(data = df_forecast, aes(x = time, y = trend), color ="red", linetype ="dashed") +geom_point(data = df_forecast, aes(x = time, y = trend), color ="red", size =2) +labs(title ="Trend Component: Fitted Linear Model and Forecast",x ="Time",y ="Trend Component") +theme_minimal()
Extract seasonal pattern
The seasonal component from the decomposition provides the repeating pattern. Since our data has a frequency of 12, we extract the seasonal indices for one complete cycle (i.e., 12 months).
# Extract the seasonal pattern (first full cycle)seasonal_pattern <- decomposed$seasonal[1:12]
Combine trend and seasonal forecasts
Assuming the residuals average to zero, the forecast for future performance is the sum of the forecasted trend and the known seasonal pattern.
Code
# Since frequency is 12, we take the first 12 months as the seasonal patternseasonal_pattern <- decomposed$seasonal[1:12]forecast_performance <- trend_forecast + seasonal_patternend_info <-end(ts_performance) # returns c(last_year, last_period)end_year <- end_info[1]end_period <- end_info[2]if(end_period ==frequency(ts_performance)) { start_year <- end_year +1 start_month <-1} else { start_year <- end_year start_month <- end_period +1}start_date <-as.Date(sprintf("%d-%02d-01", start_year, start_month))future_dates <-seq(start_date, by ="month", length.out =12)# Create a data frame with forecast dates and valuesforecast_df <-data.frame(Date = future_dates, Forecast = forecast_performance)# Plot forecastggplot(forecast_df, aes(x = Date, y = Forecast)) +geom_line(color ="blue") +geom_point(color ="red") +ggtitle("Forecasted Athletic Performance") +xlab("Date") +ylab("Performance Score")
Seasonal Regression & SARIMA Modeling
Question: “Can we quantify how much each month affects performance, and forecast future performance using seasonal models?”
Seasonal regression
A regression model with monthly dummy variables can help answer, for instance: “How much better is performance in July compared to January?”
# Create a data frame with a date sequence representing monthsdates <-seq(as.Date("2020-01-01"), by ="month", length.out =120)performance_df <-data.frame(Date = dates, Performance =as.numeric(ts_performance))performance_df$Month <-factor(format(performance_df$Date, "%m"))# Fit a regression model with monthly dummiesseasonal_model <-lm(Performance ~ Month, data = performance_df)summary(seasonal_model)
Series: ts_performance
ARIMA(0,0,0)(0,1,2)[12]
Coefficients:
sma1 sma2
-1.0450 0.1803
s.e. 0.1534 0.1146
sigma^2 = 0.8686: log likelihood = -154.03
AIC=314.07 AICc=314.3 BIC=322.11
Training set error measures:
ME RMSE MAE MPE MAPE MASE
Training set -0.03598833 0.8759365 0.6619653 -0.0873729 1.332821 0.59219
ACF1
Training set 0.04221482
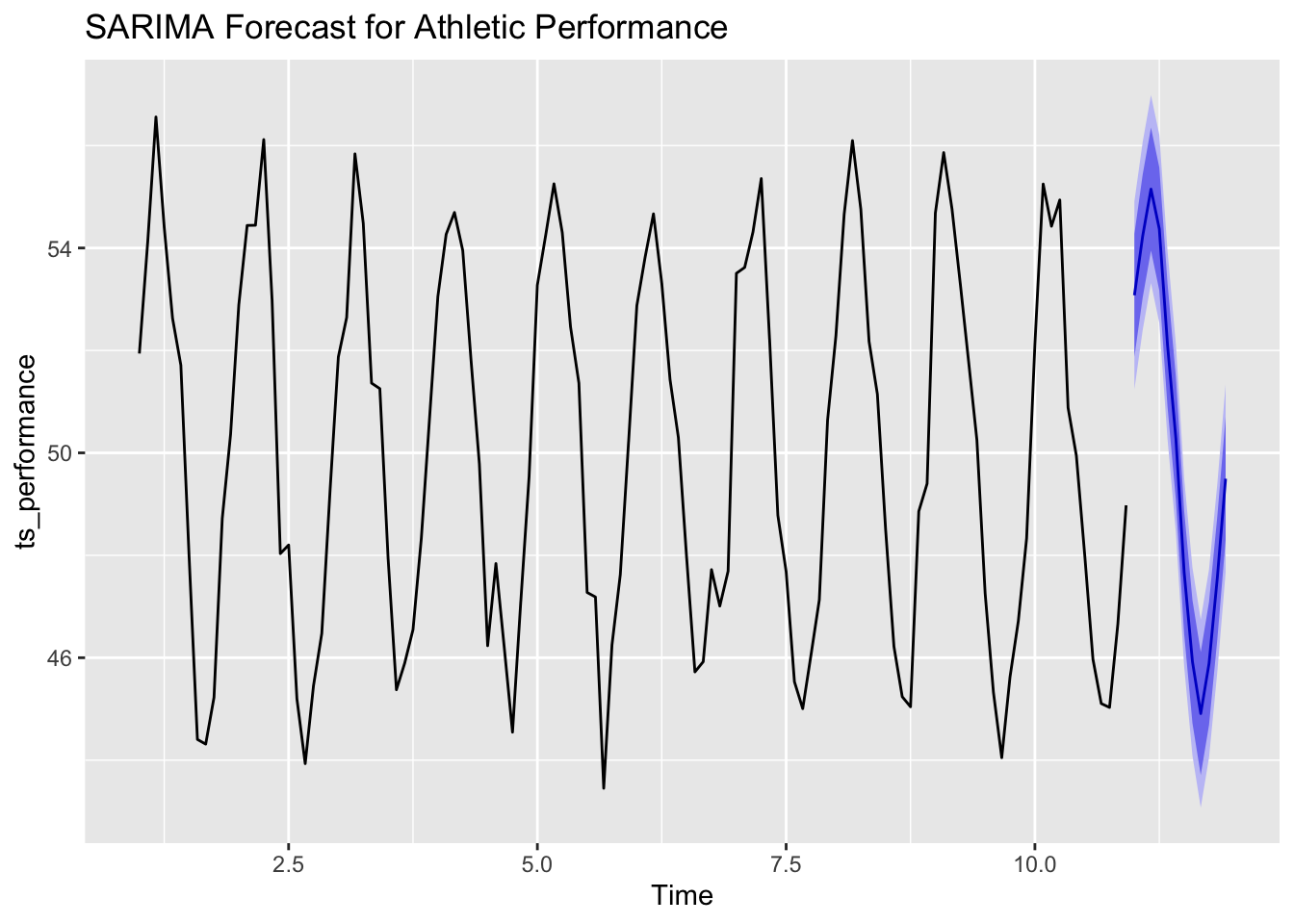
forecast_sarima <-forecast(sarima_model, h =12)autoplot(forecast_sarima) +ggtitle("SARIMA Forecast for Athletic Performance")
Interpretation:
The forecast shows predicted performance scores along with confidence intervals that reflect seasonal peaks and valleys.
Advanced Diagnostics
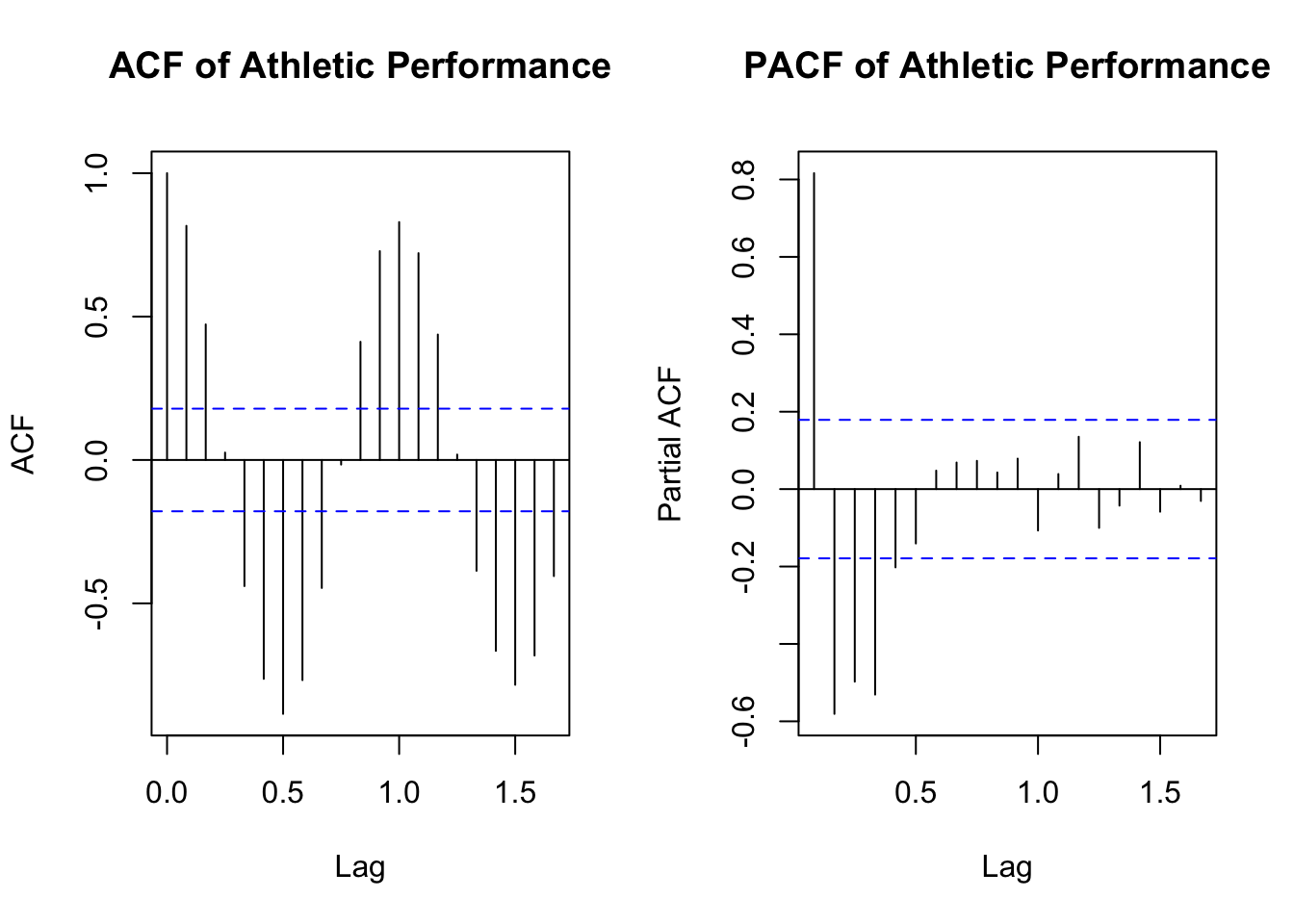
Use ACF/PACF plots and residual checks to ensure the model is properly capturing the underlying patterns:
par(mfrow =c(1,2))acf(ts_performance, main ="ACF of Athletic Performance")pacf(ts_performance, main ="PACF of Athletic Performance")
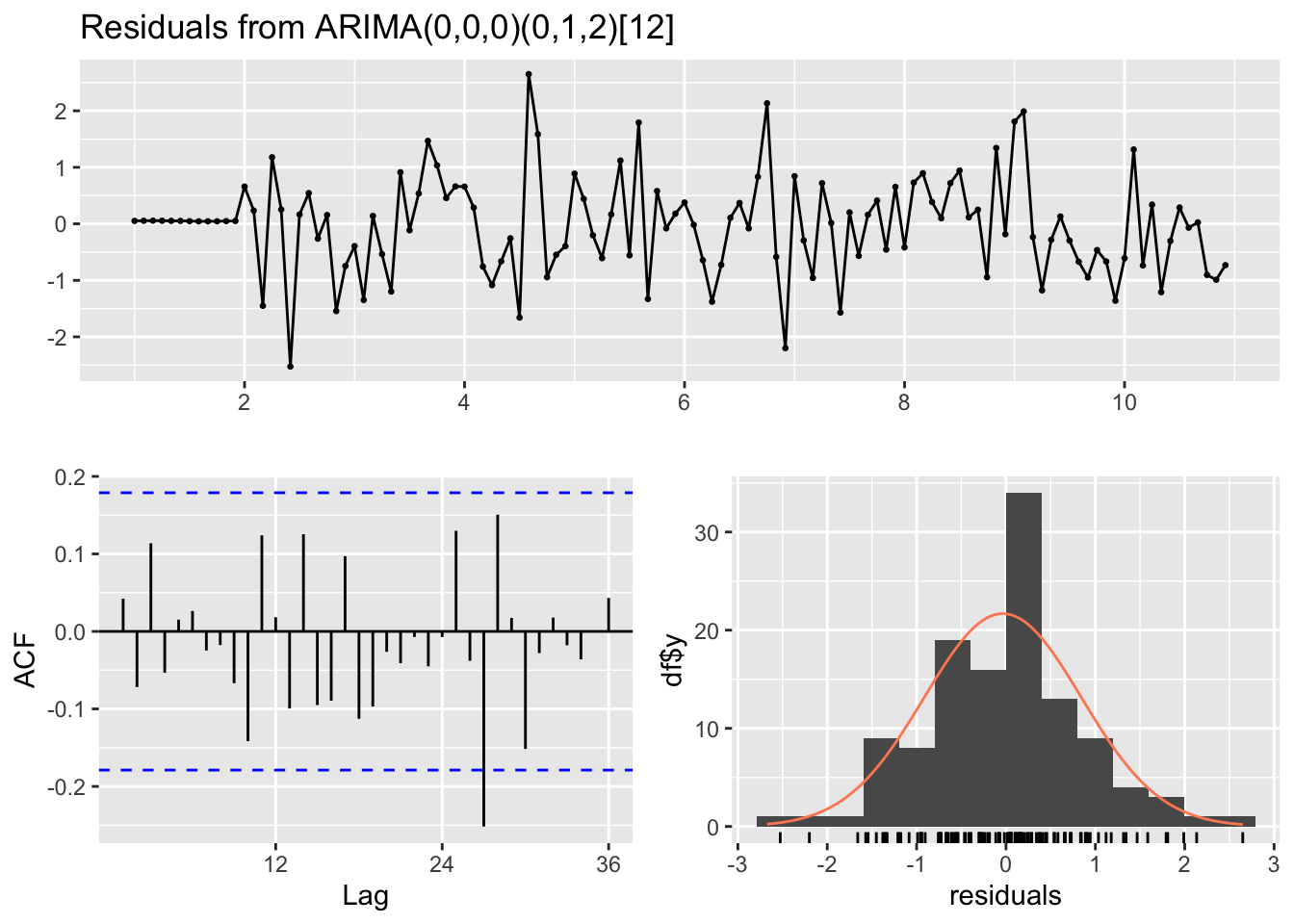
par(mfrow =c(1,1))checkresiduals(sarima_model)
Ljung-Box test
data: Residuals from ARIMA(0,0,0)(0,1,2)[12]
Q* = 19.543, df = 22, p-value = 0.6116
Model df: 2. Total lags used: 24
Interpretation:
Residual diagnostics help verify that the model has removed any serial correlation, ensuring reliable forecasts.
Panel Data Models: Multiple Athletes Across Competitions
Question: “How do individual differences among athletes affect performance across multiple competitions, and which athletes are expected to improve?”
Imagine you’re tracking performance scores for 10 athletes over 5 competitions.
The following code simulates such panel data, where each athlete has a unique baseline and each competition introduces its own effect:
library(plm)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:plm':
between, lag, lead
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
set.seed(123)n_athletes <-10# 10 athletesn_competitions <-5# 5 competitions# Create panel dataathlete <-factor(rep(1:n_athletes, each = n_competitions))competition <-rep(1:n_competitions, times = n_athletes)# Simulate athlete-specific effects and competition-specific effectsathlete_effect <-rep(rnorm(n_athletes, mean =5, sd =1), each = n_competitions)competition_effect <-rep(rnorm(n_competitions, mean =0, sd =1), times = n_athletes)error <-rnorm(n_athletes * n_competitions, mean =0, sd =2)performance_score <-50+0.8* competition + athlete_effect + competition_effect + error# Combine into a data framepanel_data <-data.frame(athlete, competition, performance_score)head(panel_data)
To control for unobserved, athlete-specific characteristics that might affect performance:
# Fixed Effects (FE) model: controls for athlete-specific factorsfe_model <-plm(performance_score ~ competition, data = panel_data, index =c("athlete", "competition"), model ="within")# Random Effects (RE) model: assumes athlete effects are randomre_model <-plm(performance_score ~ competition, data = panel_data, index =c("athlete", "competition"), model ="random")# Compare models using the Hausman testlibrary(lmtest)
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
phtest(fe_model, re_model)
Hausman Test
data: performance_score ~ competition
chisq = 8.7715e-15, df = 4, p-value = 1
alternative hypothesis: one model is inconsistent
Interpretation:
A significant Hausman test suggests that the FE model is more appropriate, meaning that individual athlete differences are correlated with competition effects.
If RE is acceptable, you can generalise findings across a broader population of athletes.
Forecasting with Panel Data
Panel data models can be used to forecast an athlete’s performance in future competitions.
For instance, to forecast for the next competition (e.g., competition 6), you might extend the trend from your model.
Here’s a simple illustration using the FE model:
library(plm)library(dplyr)# Estimate the Random Effects (RE) modelre_model <-plm(performance_score ~ competition, data = panel_data, index =c("athlete", "competition"), model ="random")# Extract overall coefficients from the RE modelmodel_coef <-coef(re_model)overall_intercept <- model_coef["(Intercept)"]beta_re <- model_coef["competition"]# 1. Population-Level (or New Athlete) Forecast for Competition 6:population_forecast <- overall_intercept + beta_re *6cat("Population-level forecast for Competition 6:", population_forecast, "\n")
Population-level forecast for Competition 6: NA
# 2. Individual Athlete Forecasts using their random effects:# Extract random effects for each athlete as a named vectorre_effects_vec <-as.vector(ranef(re_model))athlete_names <-names(ranef(re_model))re_effects_df <-data.frame(athlete = athlete_names, random_effect = re_effects_vec)# For each athlete: Forecast = overall_intercept + beta_re * 6 + athlete's random effectindividual_forecasts <- re_effects_df %>%mutate(Forecast = overall_intercept + beta_re *6+ random_effect)print(individual_forecasts)
athlete random_effect Forecast
1 1 -0.20196725 NA
2 2 -0.92080159 NA
3 3 0.68342027 NA
4 4 0.59546048 NA
5 5 0.15289934 NA
6 6 1.14605455 NA
7 7 -0.05111622 NA
8 8 -0.41070505 NA
9 9 -0.19571145 NA
10 10 -0.79753307 NA
Forecast Opportunity:
The random effect represents the estimated deviation of each athlete from the overall (population-level) baseline performance.
In other words, it quantifies how much better or worse an athlete performs relative to the average athlete once the common factors (like the overall intercept and the effect of competition) have been accounted for.
Beyond ARIMA: Hybrid & Combined Approaches in Athletics
Question: “How can we combine seasonal decomposition with athlete panel data to forecast performance trends across the season?”
Hybrid Approaches
For instance, if you have panel data where each athlete’s monthly performance exhibits seasonality, you can:
Step 1: Decompose each athlete’s performance series using methods like STL (Seasonal-Trend Decomposition). Step 2: Extract the trend components and model them using panel regression to control for athlete-specific factors. Step 3: Combine the forecasted trend with the average seasonal pattern to predict future performance. This combined method leverages the clarity of seasonal decomposition with the robustness of panel data analysis, offering nuanced insights into performance management.
# Load required librarieslibrary(dplyr)library(tidyr)library(purrr)library(ggplot2)library(forecast)library(plm)set.seed(123)n_athletes <-10n_months <-36# Data for 36 months# Simulate monthly performance:# - Each athlete has a unique effect# - Global trend over time# - Seasonal component (periodic, with period 12)# - Random noiseathlete <-factor(rep(1:n_athletes, each = n_months))month <-rep(1:n_months, times = n_athletes)athlete_effect <-rep(rnorm(n_athletes, mean =0, sd =3), each = n_months)trend_component <-0.2* month # Global trend componentseasonal_component <-5*sin(2* pi * month/12) # Seasonal patternnoise <-rnorm(n_athletes * n_months, 0, 2)performance <-50+ athlete_effect + trend_component + seasonal_component + noisedata <-data.frame(athlete = athlete, month = month, performance = performance)head(data)
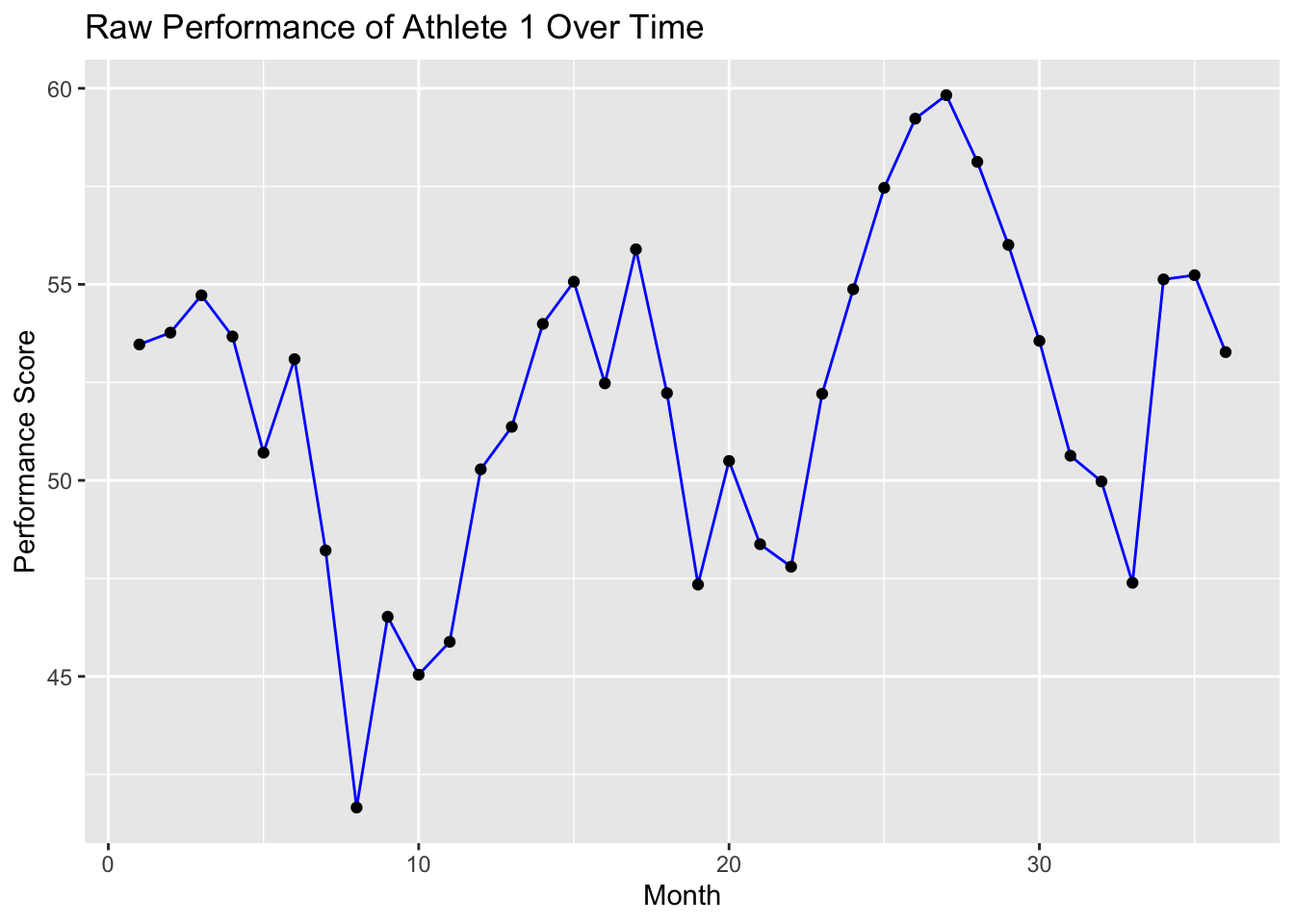
# Plot Raw Performance for a Single Athlete# visualise raw performance of athlete 1 over time.data %>%filter(athlete =="1") %>%ggplot(aes(x = month, y = performance)) +geom_line(color ="blue") +geom_point() +ggtitle("Raw Performance of Athlete 1 Over Time") +xlab("Month") +ylab("Performance Score")
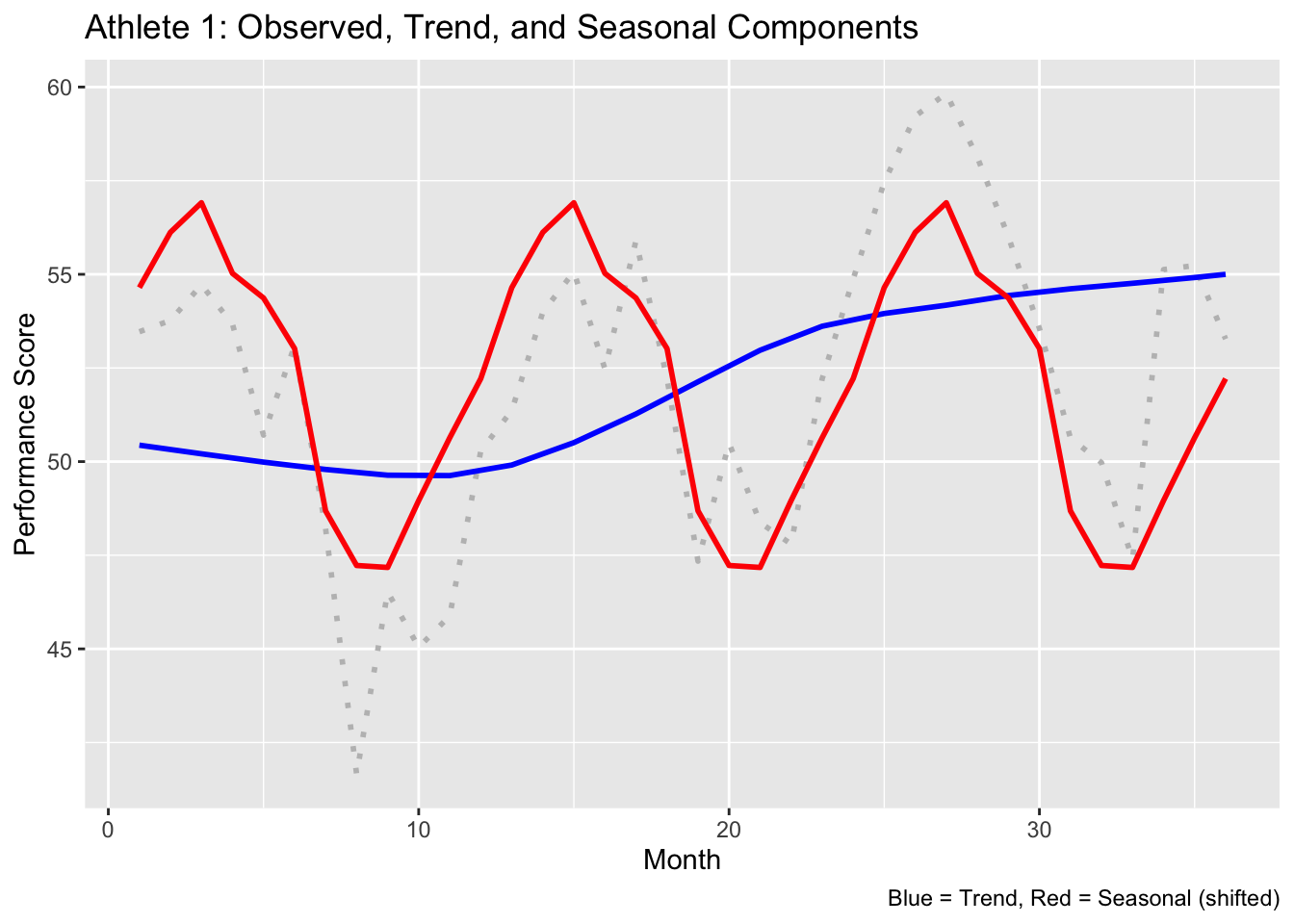
# Seasonal Decomposition (STL)# Nest data by athlete - each athlete's performance series can be decomposed individually.data_nested <- data %>%group_by(athlete) %>%nest()# For each athlete, create a time series object (with frequency 12) and perform STL decomposition.# Then immediately extract the trend and seasonal components.data_nested <- data_nested %>%mutate(ts_obj =map(data, ~ts(.x$performance, frequency =12)),stl_decomp =map(ts_obj, ~stl(.x, s.window ="periodic")),trend =map(stl_decomp, ~as.numeric(.x$time.series[, "trend"])),seasonal =map(stl_decomp, ~as.numeric(.x$time.series[, "seasonal"]))) %>%# Remove the raw time series and STL objects to simplify later steps.select(-ts_obj, -stl_decomp)# Visualisation: Decomposition for Athlete 1# Extract data for athlete 1 and create a data frame for plotting.athlete1 <- data_nested %>%filter(athlete =="1")athlete1_decomp <-data.frame(month =1:n_months,trend = athlete1$trend[[1]],seasonal = athlete1$seasonal[[1]],observed = data %>%filter(athlete =="1") %>%pull(performance))# Plot observed performance, trend, and seasonal componentsggplot(athlete1_decomp, aes(x = month)) +geom_line(aes(y = observed), color ="gray", size =1, linetype ="dotted") +geom_line(aes(y = trend), color ="blue", size =1) +geom_line(aes(y = seasonal +mean(observed)), color ="red", size =1) +ggtitle("Athlete 1: Observed, Trend, and Seasonal Components") +xlab("Month") +ylab("Performance Score") +labs(caption ="Blue = Trend, Red = Seasonal (shifted)")
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
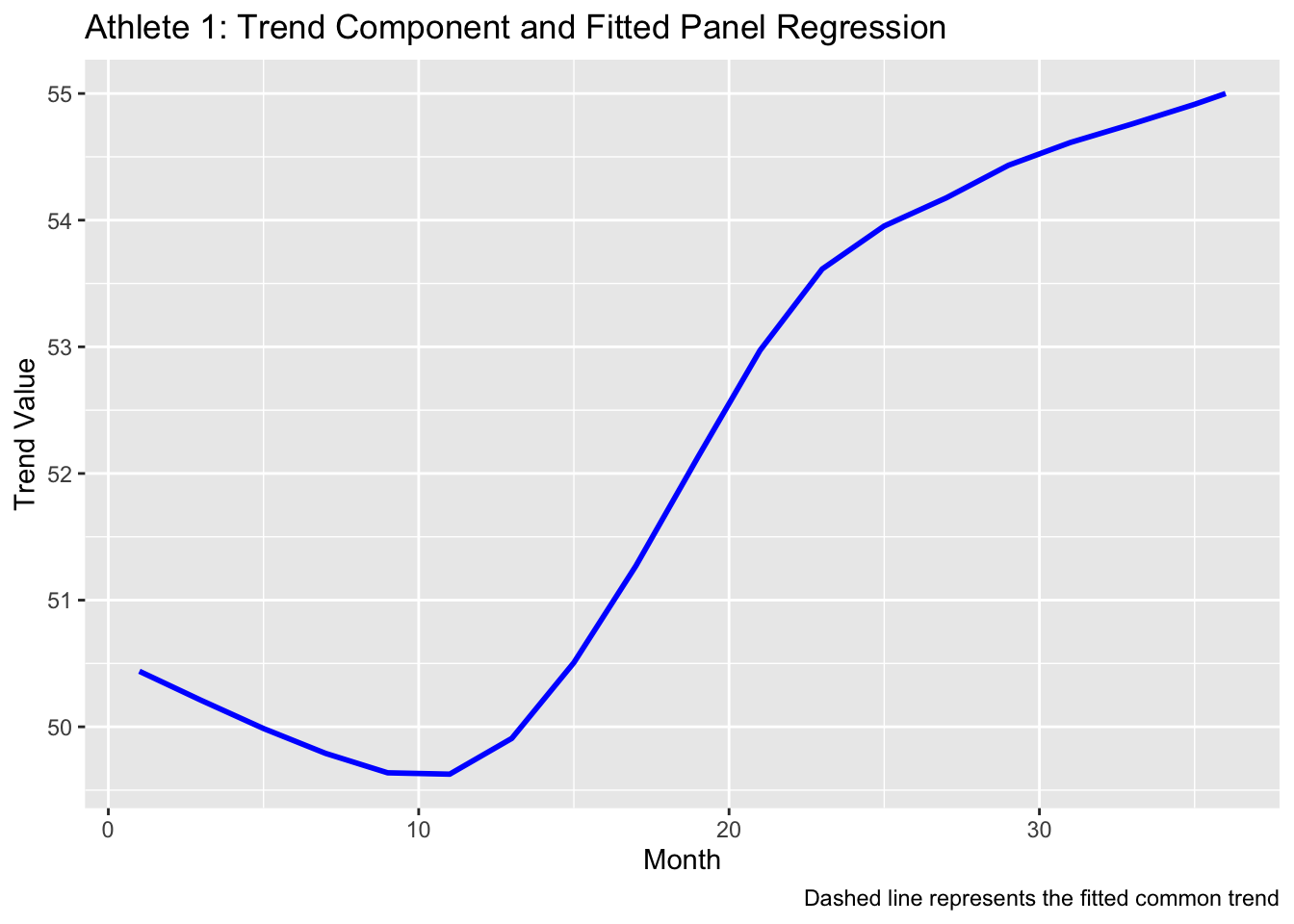
# Modeling Trend Component via Panel Regression# Unnest trend values along with a month index for each athlete.trend_data <- data_nested %>%select(athlete, trend) %>%mutate(month =list(1:n_months)) %>%# Create a month index for each athleteunnest(cols =c(month, trend)) %>%rename(trend_value = trend)# Run a panel regression (pooled model) on the extracted trend component.trend_panel <-plm(trend_value ~ month, data = trend_data, index =c("athlete", "month"), model ="pooling")summary(trend_panel)
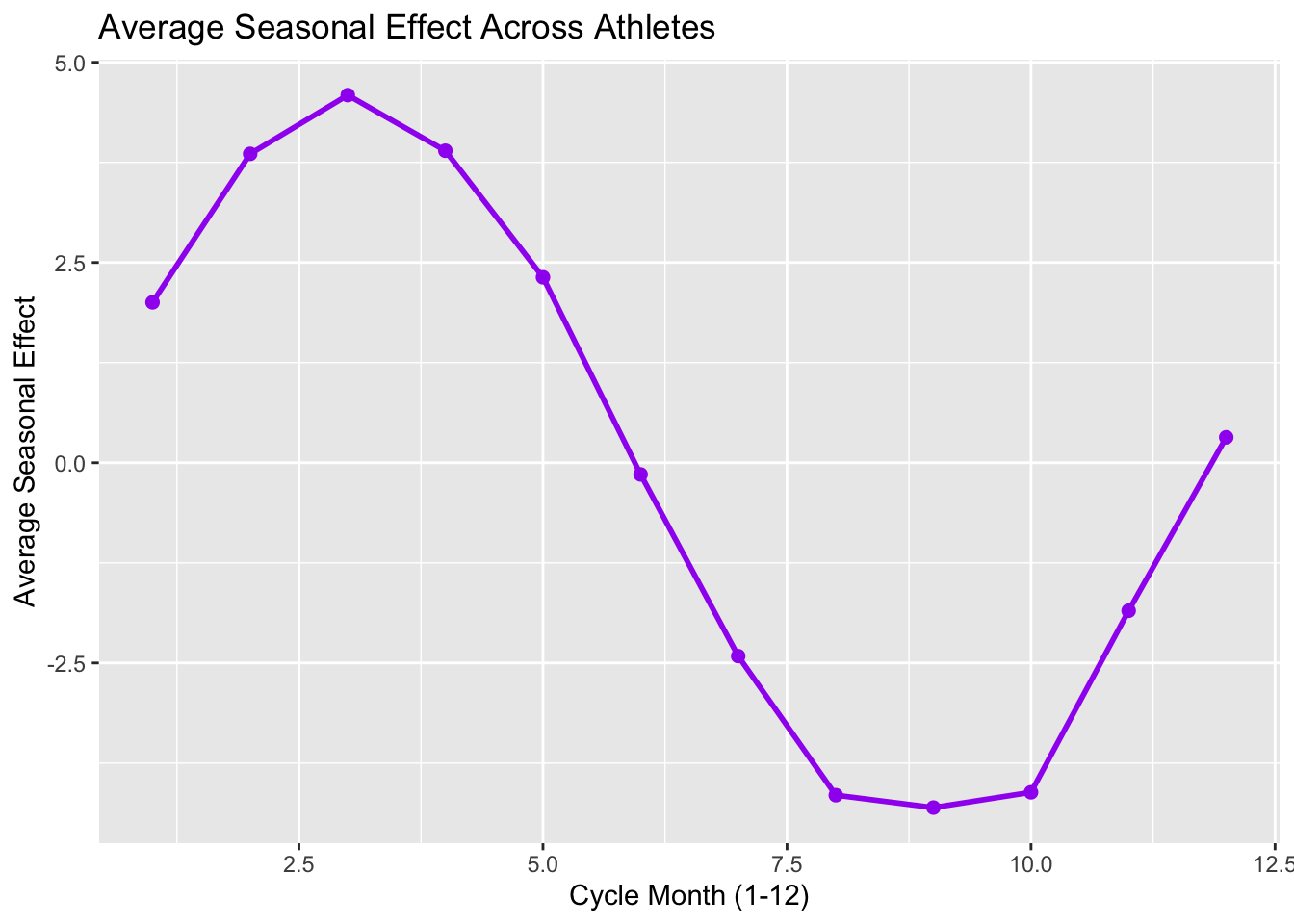
# Plot the Average Seasonal Patternggplot(avg_seasonal, aes(x = cycle_month, y = avg_seasonal)) +geom_line(color ="purple", size =1) +geom_point(color ="purple", size =2) +ggtitle("Average Seasonal Effect Across Athletes") +xlab("Cycle Month (1-12)") +ylab("Average Seasonal Effect")
# For forecasting month 37, determine its cycle month.forecast_cycle_month <- ((37-1) %%12) +1# For month 37, cycle_month will be 1seasonal_forecast_value <- avg_seasonal %>%filter(cycle_month == forecast_cycle_month) %>%pull(avg_seasonal)# Final combined forecast# The final forecast for month 37 is sum of forecasted trend and seasonal effect.final_forecast <- trend_forecast_value + seasonal_forecast_valuecat("Forecasted performance for month 37:", final_forecast, "\n")